




In previous posts on cognate identification, I discussed the difference between strict and loose cognates. Loose cognates are words in two languages that have the same or similar written forms. I also described how approaches to cognate identification tend to differ based on whether the data being used is plain text or phonetic transcriptions. The type of data informs the methods. With plain text data, it is difficult to extract phonological information about the language so approaches in the past have largely been about string matching. I will discuss some of the approaches that have been taken below the jump. In my next posting, when I get around to it, I will begin looking at some of the phonetic methods that have been applied to the task.
Simple String Matching
Simple string matching involves matching identical substrings in the word pair. Throughout this document, word pair will mean the two words in separate languages being considered to determine their status as cognates. Simard et al. (1993) used a measure of cognateness based on matching the first four letters in each word. They used this cognateness measure to align sentences in a bilingual corpus (the Hansards). Their hypothesis was that there would be more cognates in aligned substrings than in non-aligned. They hand aligned a portion of the Hansards and found that there was a statistically significantly higher number of cognates in aligned parts.
Dice’s Coefficient
Dice’s coefficient is another string similarity measure that has been used for cognate identification. Given two aligned hypotheses, Dice’s coefficient is calculated as
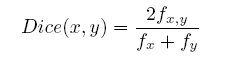
where f_x,y is the co-occurrence of items in the aligned set and f_x and f_y are the two sets under consideration. As with any string similarity score, pairs of strings that are rated as more similar can be considered to be cognates.
Longest Common Subsequence Ratio
The Longest Common Subsequence Ratio (LCSR) is another measure of string similarity that takes advantage of the observation that parts of a string may be similar while the prefixes and suffixes are not (or any other part of the string). The LCSR is computed by finding the longest substring in common between the two strings and returning the ratio of the length of that string to the length of the longest of the two words in the pair. This then becomes a measure of the two words’ cognateness.
Tiedemann’s Three String Similarity Measures
Joerg Tiedemann (1999) developed three string similarity measures that lie at the boundary of what I consider orthographic methods. Whereas other string similarity measures make no distinction between the individual characteristics of letters, Tiedemann’s measures do. In particular, he makes a distinction between vowels and consonants and the distributions that generate them.
His algorithms rely on a dynamic programming technique from Stephen (1992) to compute the LCS. A matrix is created with n rows and m columns, where n is the length of the first string and m is the length of the second. Beginning at position 0 (before the first character in both strings), a string matching function is applied to each character pair for each cell in the table. For example, this function could return 1 if the characters match according to the function and 0 if they do not. The value for each cell is computed as follows (Tiedemann, 1999):
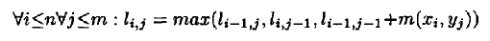
The final cell contains the LCS for these two strings if the matching function used is the example (match=1/mismatch=0) above. Tiedemann recognized that another matching function could be used. Since we are no longer computing the longest common subsequence, he chose the term highest score of correspondence (HSC).
Tiedemann describes three matching functions: VCchar, VCseq, and NMmap, where V=vowel, C=consonant, and NM=non-matching. I refer the reader to the paper (pdf) for details on each of these, but I will touch on certain aspects briefly. In VCchar, pairs of vowels and consonants that occur together more frequently are given more weight in the matching function. If they never co-occur, their value is 0. Now remember we are talking about one character from each language. Tiedemann found interesting mappings with this, like English c for Swedish k. He also found that there were spurious results and so requires tuning of a threshold function. VCseq is similar to VCchar but instead he looks at longer sequences of characters rather than single ones. NMmap takes a different approach. Instead of matching similar characters, it looks at parts of strings that are not the same. I personally found this to be the most interesting and it produced neat mappings like Swedish ska to English c (e.g. Swedish automatiska to English automatic).
References
M. Simard, G.F. Foster, and P. Isabelle. Using cognates to align sentences in bilingual corpora. In Proceedings of the 1993 Conference of the Centre for Advanced Studies on Collaborative research: Distributed Computing-Volume 2, pages 1071-82, 1993.
Stephen, Graham A. String Search. Technical Report TR-92-gas-01, School of Electronic Engineering Science, University College of North Wales, 1992.
Tiedemann, Joerg. Automatic construction of weighted string similarity measures. In Proceedings of the Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, 1999.
